不止“写得快”,金仓时序数据库破解时序数据多重难题
这正是时序场景与普通业务系统的本质区别:普通业务数据来自单次明确动作(交易、订单、审批),而时序数据是设备状态的持续上报,规模随采集点位呈指数级增长。电表遥测、风机参数、产线振动、车辆轨迹…… 只要设备运转,数据就会源源不断产生。因此,时序数据库真正要面对的,不是某一次峰值写入,而是高频采集、长期留存、持续查询三者同时存在的复合挑战。
四大核心难题不止是“写得快”
随着系统运行,问题会逐步叠加,最终压垮很多看似“高性能”的时序系统:
写入压力:设备数量和采样频率同时增长后,系统要持续承接高并发写入。写入链路不只是插入数据,还涉及内存、日志、磁盘I/O、索引维护等一整套动作。点位规模上来后,单点能力很容易被持续压住。
索引压力:时序数据看似只是“时间+数值”,但真实查询通常会带上设备ID、指标类型、区域、业务标签等条件。随着采集点增加或者历史数据增长,索引规模也会爆炸式增长。一旦B-Tree索引不能有效驻留内存,系统就会更多依赖磁盘随机I/O,写入和查询都会受到影响。
冷热混杂:工业现场既要看最新状态,也要查历史趋势。最近几分钟的数据用于告警,过去几天的数据用于分析波动,过去几个月甚至几年的数据用于故障追溯和模型训练。但是如果将所有数据都以同一种方式存储、管理,实时业务和历史分析很容易互相抢资源。
扩展和运维压力:工业系统不是临时性应用,往往要长期运行。后续继续加设备、加采样、加留存周期是常态。如果每次扩容都要停机迁移,或者依赖不断升级单机硬件,系统越往后越被动。
直击工业场景的工程解法
针对上述长期运行中的实际问题,金仓时序数据库给出了针对性的工程实现:
数据组织方面:金仓时序数据库自研创新“二维分区”算法,通过分布式超表和块级数据管理机制,并结合时间和空间两个维度的内核级精密路由:1、时间轴主分区用于控制数据块和索引规模,避免热数据范围无限扩大;2、空间轴次分区针对设备ID等标签执行哈希分区将高并发写入压力均匀分散至各数据节点,减少单一节点集中压力的风险,充分利用资源。

查询计算方面:金仓时序数据库在访问节点侧通过智能元数据路由算法,先将排序、聚合、分组等算子下发至数据节点,让计算尽量放到数据所在位置处理。很多时序查询并不需要回传全部明细数据,比如按分钟统计平均温度、按小时计算最大电流、按天汇总能耗。先在本地完成局部计算,再汇总结果,可以最大化减少数据跨节点搬运,也能降低中心节点的计算压力。结合内置的插值填补与时间桶聚合能力让原本需要分钟级的跨节点复杂分析缩短至亚秒级响应。
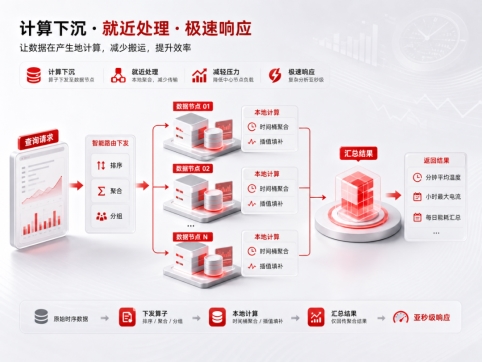
长期留存方面:金仓时序数据库通过自适应压缩、冷热分区并结合全生命周期管理体系降低数据存储和管理成本。热数据服务于实时告警和高频查询,冷数据服务于趋势分析、故障追溯和建模训练。这样处理,既不丢弃历史数据,也不把所有数据都放在高成本存储上,兼顾效率和成本。
可靠性方面:工业场景不能只看吞吐指标。生产调度、电力监测、交通运行等系统对数据一致性和业务连续性都有要求。金仓时序数据库通过事务一致性机制和多副本高可用能力,保证系统在节点异常或跨节点操作时仍然保持可控状态。
选型别被“写入峰值”带偏了
时序数据本身只是设备运行状态的一部分。要形成业务判断,还需要关联设备档案、空间位置、业务区域、运维工单等信息。金仓数据库的时序能力构建在电科金仓新一代融合数据底座中,可以与关系、文档、向量、GIS等数据结合,减少外部同步和多系统拼接。
因此,工业级时序数据库选型,不应只看 “每秒能写多少行” 的纸面指标。更关键的是:数据规模持续增长后,系统能不能继续稳定写入?历史数据越存越多后,查询能不能保持快速?设备持续接入后,架构能不能平滑扩展?业务深化后,数据能不能与其他系统关联分析?
金仓数据库始终秉承创新务实的理念,围绕客户真实业务场景中的核心挑战逐一拆解并给出工程化解决方案,真正为客户解决长期运行中的实际难题。
最新图文资讯

海底捞内部“海选”接班人,传菜小哥也有机会

注重科技融合 尽显艺术之美 《2022年春节联欢晚会》进行第四次彩排

稳就业信号增强 减负稳岗扩就业齐发力

中国网络安全产业公共服务平台正式上线发布
- 1共赴智算未来:维谛(Vertiv)亮相Computex2026,以全融合型基础设施赋能AI时代
- 2旅游新国标贯通“吃住行游购娱” 场所从“卖商品”转向“卖服务、卖体验、卖文化”
- 3目的地多元、体验深入 暑期文旅市场热度飙升蓄势待发呈现新亮点
- 4164项专利行业领先,日日顺持续打造“科技生态”
- 5核心业务稳定运行!电科金仓助力某省级公安云平台完成关键升级
- 6“美丽中国行之探访国家公园”集中采访启动
- 7远景发布全球首款AI光储一体化系统,全栈自研打通“风、光、储、氢”
- 8BEAUTY RUSH 忠于自己,不必攀比
- 9数字经济重构实体价值:中食科技与一场“兴商富民”的产业实验
- 10京东6万工程师迎战高温季! 部分地区可实现24小时空调极速送装
- 1中传世纪控股开展子公司清理规范专项工作 坚决清理假冒国企与低效企业
- 2芯位科技与清华大学共同领衔的标准成果在2026世界数字教育大会发布
- 32026年中国AI竞争格局与商业化趋势分析:梯队重构、价值兑现、生态决胜
- 4绿盟科技安全数字人平台正式发布:以风云卫为核心,构建自主运营、持续进化的安全数字人团队
- 52026年磷酸铁锂电池行业量价齐升迎拐点 技术迭代启新程
- 6叶嘉重返北音毕业典礼 献唱《听我说谢谢你》致青春
- 72026年4月汽车工业经济运行情况
- 8共赴智算未来:维谛(Vertiv)亮相Computex2026,以全融合型基础设施赋能AI时代
- 9海尔厨电618开门红:Seeker油烟机天猫热卖榜TOP1
- 10寻找高效传动方案 电动推杆品牌推荐大揭秘
